「The 2025 AI Index Report」의 Technical Performance 챕터에서는 2025년까지 이뤄진 AI의 발전을 종합적으로 정리하고 있습니다.
이번 챕터는 주요 AI 관련 발표, 현재의 AI 역량, 핵심 기술 트렌드를 요약하며 시작합니다. 여기에는 오픈 웨이트 모델(open-weight models)의 성능 향상, 최첨단 모델 간 성능 격차의 축소, 중국산 대형 언어 모델(LLM)의 품질 개선 등이 포함됩니다.
이어서 언어 이해 및 생성, 검색 기반 생성(RAG), 코딩, 수학, 추론, 컴퓨터 비전, 음성 처리, 에이전트형 AI 등 다양한 AI 기능의 현재 수준을 살펴봅니다. 올해는 특히 로보틱스와 자율주행 자동차의 성능 트렌드에 대한 분석이 크게 확대되었습니다.

목차
- 놀라운 벤치마크 정복 속도
- 공개 가중치 모델의 성능 발전
- 미국과 중국의 성능 경쟁
- AI 모델의 상향 평준화
- 새로운 추론 방식의 등장
- 엄격해지는 AI 벤치마크
- 고품질 AI 영상 생성기
- 소형 AI 모델의 강력한 성능
- 여전히 해결되지 않은 과제
- 에이전트의 가능성
이 포스팅은 Standford HAI가 2025년 4월에 발행한 「The 2025 AI Index Report」의 일부 내용을 요약하고 의역한 글입니다.
보고서의 정확한 내용이 궁금하신 분들은 원문(영어)을 참고해 주세요.

1. 놀라운 벤치마크 정복 속도
AI는 새로운 벤치마크를 그 어느 때보다 빠르게 정복하고 있습니다.
2023년, 연구자들은 고성능 AI 시스템의 한계를 시험하기 위해 MMMU, GPQA, SWE-bench 등 도전적인 새로운 벤치마크를 도입했습니다.
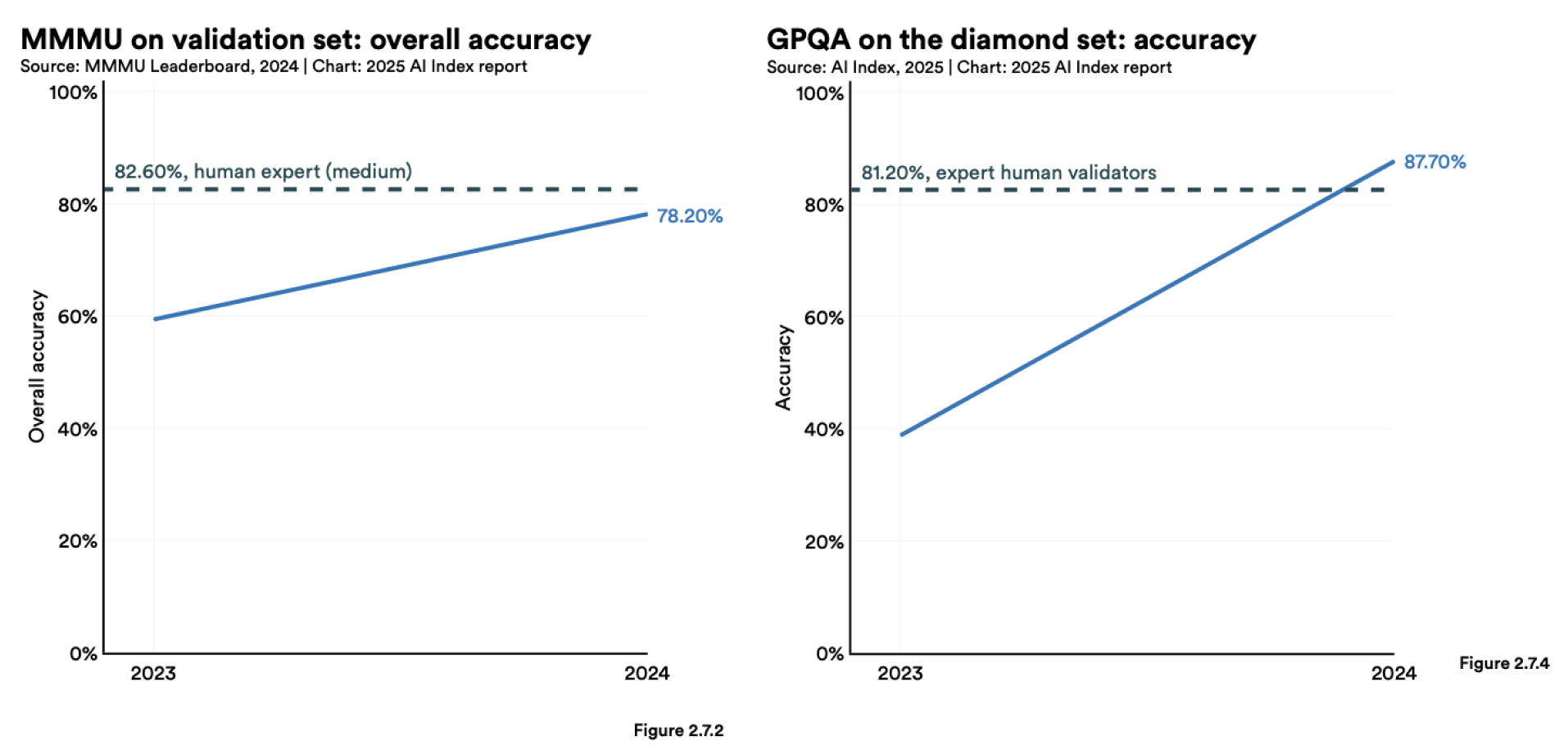
2024년에는 이러한 벤치마크에서의 AI 성능이 눈에 띄게 향상되었는데, MMMU와 GPQA에서 각각 18.8포인트와 48.9포인트의 상승이 있었습니다.
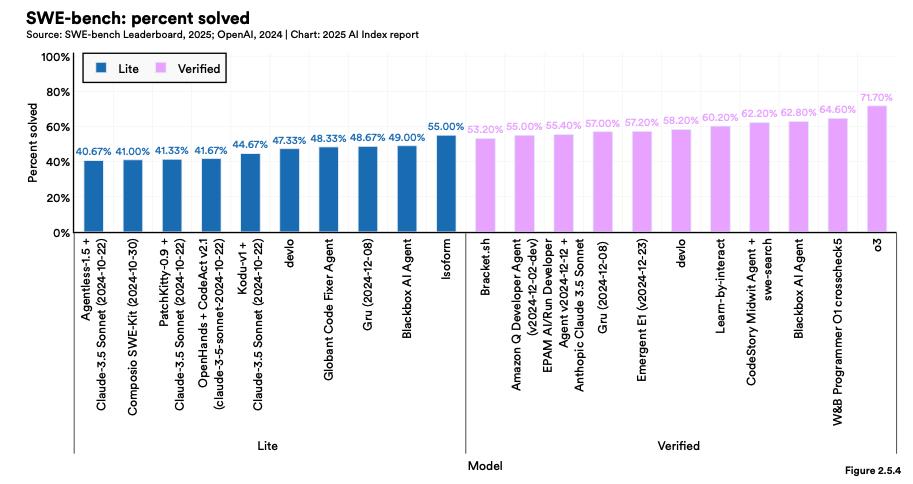
SWE-bench의 경우, 2023년에는 AI가 코딩 문제의 4.4%만 해결할 수 있었으나, 2024년에는 이 수치가 71.7%로 급등했습니다.
2. 공개 가중치 모델의 성능 발전
공개 가중치(Open-weights Model, AI 모델의 성능을 좌우하는 가중치 값을 공개한 모델) 모델의 성능이 비공개 모델의 성능을 빠르게 추격하고 있습니다.
2024년에는 오픈 웨이트 모델이 비공개 모델에 비해 성능이 상당히 뒤처진다고 지적되었지만, 2024년에는 그 격차가 거의 사라졌습니다.

2024년 1월 초만 해도 Chatbot Arena Leaderboard에서 최고 비공개 모델이 최고 오픈 웨이트 모델보다 8.0% 높은 점수를 기록했으나, 2025년 2월에는 그 차이가 1.7%로 줄어들었습니다.
3. 미국과 중국의 성능 경쟁
중국과 미국 모델 간 성능 격차가 좁아지고 있습니다.
2023년에는 미국 모델이 중국 모델에 비해 현저한 우위를 보였지만, 이제는 더 이상 그런 경향이 지속되지 않습니다.

2023년 말 기준으로 MMLU, MMMU, MATH, HumanEval 등의 벤치마크에서 성능 격차는 각각 17.5, 13.5, 24.3, 31.6포인트였지만, 2024년 말에는 이 격차가 각각 0.3, 8.1, 1.6, 3.7포인트로 크게 좁혀졌습니다.

4. AI 모델의 상향 평준화
최첨단 AI 모델 간 성능 격차가 수렴하고 있습니다. 작년 AI 인덱스에 따르면, Chatbot Arena Leaderboard에서 1위와 10위 모델 간의 Elo 점수 차이는 11.9%였습니다. 그러나 2025년 초에는 이 차이가 5.4%로 줄어들었습니다.

마찬가지로, 1위와 2위 모델 간의 점수 차이도 2023년 4.9%에서 2024년에는 단 0.7%로 감소했습니다. 이는 고품질 AI 모델이 점점 더 많은 개발자들에 의해 출시되면서, AI 시장이 갈수록 경쟁적으로 변하고 있다는 것을 보여줍니다.

5. 새로운 추론 방식의 등장
테스트 타임 컴퓨트(test-time compute)와 같은 새로운 추론 방식이 모델 성능을 향상시키고 있습니다.
2024년, OpenAI는 출력 결과를 반복적으로 추론하는 방식으로 설계된 o1 및 o3 모델을 선보였습니다. 이러한 테스트 타임 컴퓨트 방식은 성능을 극적으로 끌어올렸으며, o1 모델은 국제 수학 올림피아드 예선 시험에서 74.4%의 점수를 기록했습니다.
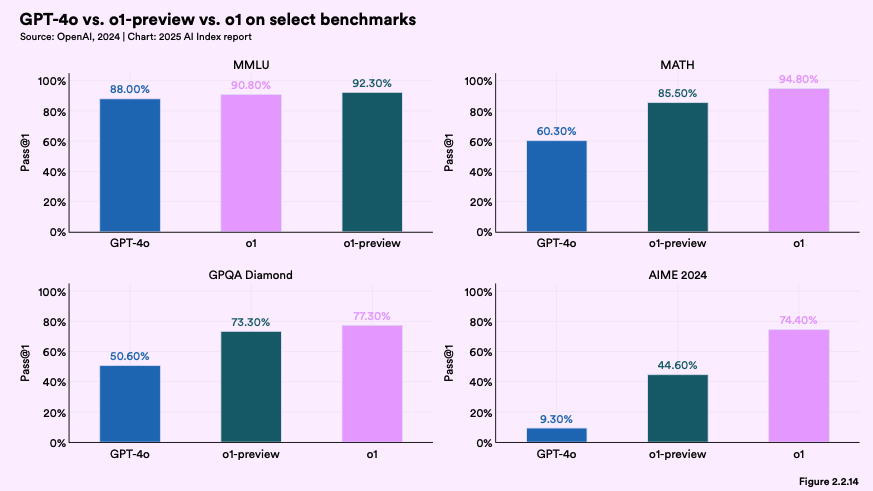
이는 GPT-4o가 기록한 9.3%와 비교할 때 매우 높은 수치입니다. 하지만 이처럼 향상된 추론 능력에는 대가가 따릅니다. o1 모델은 GPT-4o보다 약 6배 비싸고, 속도는 30배나 느립니다.
6. 엄격해지는 AI 벤치마크
더욱 도전적인 벤치마크들이 계속해서 제안되고 있습니다.
기존 AI 벤치마크(MMLU, GSM8K, HumanEval 등)의 성능이 포화 상태에 도달하고, MMMU 및 GPQA와 같은 더 어려운 벤치마크에서도 성능이 향상되면서, 연구자들은 선도적인 AI 시스템을 평가하기 위한 새로운 방법을 모색하고 있습니다.
대표적인 예로는 Humanity’s Last Exam이 있습니다. 이 시험은 매우 엄격한 학문적 테스트로, 최고 성능 AI(o1)조차도 겨우 8.80%를 기록했습니다.

또 다른 예로 BigCodeBench는 코딩 능력을 측정하는 벤치마크로, AI는 35.5%의 성공률을 보였으며 이는 인간 표준인 97%에 크게 못 미치는 수치입니다.

7. 고품질 AI 영상 생성기
고품질 AI 영상 생성기가 눈에 띄게 발전하고 있습니다. 2024년에는 텍스트 입력을 기반으로 고화질 영상을 생성할 수 있는 고급 AI 모델들이 다수 출시되었습니다.
주요 모델로는 OpenAI의 SORA, Stable Video Diffusion 3D 및 4D, Meta의 Movie Gen, Google DeepMind의 Veo 2가 있습니다. 이들 모델은 2023년에 비해 훨씬 더 높은 품질의 영상을 생성할 수 있습니다.
8. 소형 AI 모델의 강력한 성능
소형 모델이 더 강력한 성능을 보여 주고 있습니다.
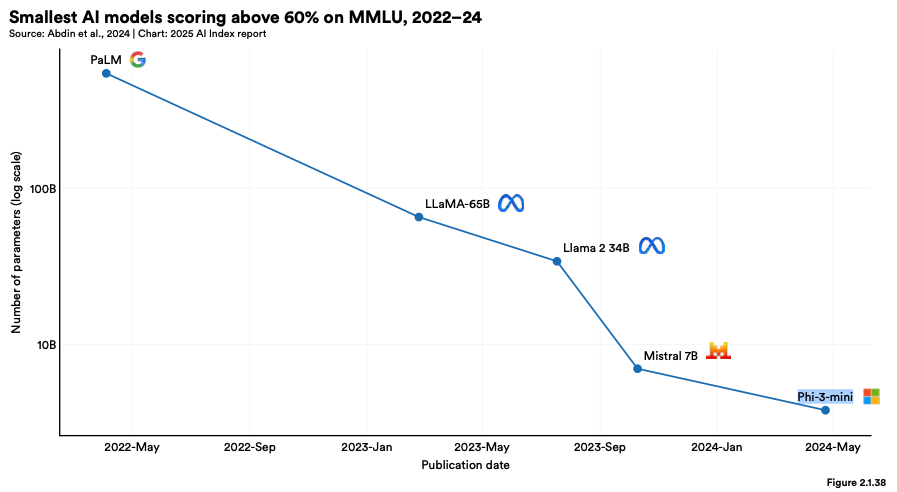
2022년 MMLU에서 60% 이상의 점수를 기록한 가장 작은 모델은 5400억 개의 파라미터를 가진 PaLM이었습니다. 그러나 2024년에는 Microsoft의 Phi-3-mini가 단 38억 개의 파라미터로 같은 성능을 달성했습니다. 이는 2년 만에 모델 크기를 142분의 1로 줄인 성과입니다.
9. 여전히 해결되지 않은 과제
복잡한 추론은 여전히 해결되지 않은 과제입니다.
체인 오브 소트(chain-of-thought) 추론 같은 메커니즘의 도입으로 LLM의 성능은 크게 향상되었지만, 여전히 논리적 추론을 통해 정답을 도출할 수 있는 문제(예: 산술 연산, 계획 수립 등)를 안정적으로 해결하지는 못합니다.
특히 학습 데이터보다 규모가 큰 문제에서는 더욱 그러하며, 이는 이러한 시스템의 신뢰성과 고위험 환경에서의 활용 가능성에 중요한 영향을 미칩니다.
10. AI 에이전트의 가능성
AI 에이전트는 초기 단계에서 유망한 가능성을 보이고 있습니다.
2024년 RE-Bench의 도입으로 복잡한 작업을 평가하기 위한 엄격한 벤치마크가 마련되었습니다.

짧은 시간 예산(2시간) 안에서는 최고의 AI 시스템이 인간 전문가보다 4배 높은 점수를 기록했지만, 시간이 길어질수록 인간의 성과가 AI를 능가하여 32시간 예산에서는 2배 이상의 차이로 앞섰습니다.
현재 AI 에이전트는 특정 작업에서 인간 전문가와 동등한 수준의 성과를 보이며, 더 빠르고 비용 효율적인 결과를 제공하기도 합니다.
'인공지능 > AI 인사이트' 카테고리의 다른 글
| [Stanford HAI] "AI 정책 분야" 핵심 요약 (The 2025 AI Index Report) (3) | 2025.08.03 |
|---|---|
| [Stanford HAI] "과학 및 의학 분야" 핵심 요약 (The 2025 AI Index Report) (1) | 2025.08.03 |
| [Stanford HAI] "경제 분야" 핵심 요약 (The 2025 AI Index Report) (2) | 2025.08.03 |
| [Stanford HAI] "책임 있는 AI 분야" 핵심 요약 (The 2025 AI Index Report) (2) | 2025.08.03 |
| [Stanford HAI] "연구 개발 분야" 핵심 요약 (The 2025 AI Index Report) (0) | 2025.08.02 |
| [McKinsey / Bain / BCG] 3대 컨설팅사 주요 AI 인사이트 번역 & 정리 (25.04~25.05) (0) | 2025.05.31 |
| [Bain] 전통적인 마케팅 퍼널의 위기: 제로 클릭 퍼널과 AI 에이전트 (25.04) (0) | 2025.05.31 |
| [BCG] AI로 변화하는 은행의 경쟁 패러다임 (25.05) (0) | 2025.05.31 |



